「Python初心者必見!Matplotlibによるデータ可視化の基礎」
【はじめに】
Matplotlibは、Pythonのデータ可視化ライブラリの中でも最も有名で、使われている頻度が高いライブラリの一つです。Matplotlibを使うことで、グラフやチャートなどの視覚化を行うことができます。本記事では、Matplotlibの基礎的な使い方について説明します。
【1. グラフの描画】
まずは、Matplotlibを使って簡単なグラフを描画してみましょう。以下のようなコードを実行すると、グラフが表示されます。

上記のコードでは、`matplotlib.pyplot`を`plt`としてインポートしています。また、`x`と`y`は、それぞれグラフの横軸と縦軸の値を表しています。`plt.plot(x, y)`でグラフを描画し、`plt.show()`でグラフを表示しています。
【2. グラフのスタイルの設定】
次に、グラフのスタイルを設定する方法について説明します。以下のように、`color`や`linestyle`などのパラメータを指定することで、グラフのスタイルを変更することができます。

上記のコードでは、`color`に赤色を指定し、`linestyle`に破線を指定しています。また、グラフのタイトルや軸ラベルも設定しています。
【3. 複数のグラフの描画】
Matplotlibでは、複数のグラフを同時に描画することもできます。以下のように、`plt.subplots()`で複数のグラフを設定し、`ax[i].plot()`で各グラフの描画を行います。

上記のコードでは、`fig, ax = plt.subplots(2, 1)`で2つのグラフを設定しています。`ax[0].plot(x, y1)`で1つ目のグラフを描画し、`ax[1].plot(x, y2)`で2つ目のグラフを描画しています。
【4. 散布図の描画】
Matplotlibを使って、散布図を描画することもできます。以下のようなコードを実行すると、散布図が表示されます。

上記のコードでは、`plt.scatter()`で散布図を描画しています。また、グラフのタイトルや軸ラベルも設定しています。
【5. ヒストグラムの描画】
Matplotlibを使って、ヒストグラムを描画することもできます。以下のようなコードを実行すると、ヒストグラムが表示されます。

上記のコードでは、`np.random.normal()`で正規分布に従う乱数を生成し、`plt.hist()`でヒストグラムを描画しています。また、グラフのタイトルや軸ラベルも設定しています。
【おわりに】
以上、Matplotlibによるデータ可視化の基礎について説明しました。Matplotlibは、Pythonのデータ可視化ライブラリの中でも最も有名で、使われている頻度が高いライブラリの一つです。これらの基礎を身につけることで、データの視覚化をより効果的に行うことができます。
【Pandasによるデータ分析の基礎】
【Pandasによるデータ分析の基礎】
Pandasは、Pythonのデータ分析ライブラリの中でも特に広く使われているものです。Pandasを使うことで、簡単かつ効率的にデータを扱うことができます。本記事では、Pandasを使ったデータ分析の基礎を解説します。
【1. Pandasのインストール】
まずは、Pandasをインストールしましょう。Pandasは、pipコマンドを使って簡単にインストールできます。ターミナル(コマンドプロンプト)を開いて、以下のコマンドを実行してください。

【2. データの読み込み】
次に、分析したいデータを読み込みます。Pandasには、CSVやExcelなど、様々な形式のファイルを読み込むための関数が用意されています。ここでは、CSVファイルを読み込む例を紹介します。

上記のコードでは、Pandasを`pd`としてインポートし、`read_csv()`関数を使って、`data.csv`というファイルを読み込んでいます。読み込んだデータは、DataFrameと呼ばれるPandasのデータ構造に格納されます。
【3. データの確認】
読み込んだデータが正しくDataFrameに格納されたかどうかを確認しましょう。DataFrameには、`.head()`関数や`.tail()`関数を使って、先頭や末尾の数行を表示することができます。

【4. データの加工】
DataFrameに格納されたデータを加工して、必要な情報を抽出することができます。Pandasには、データのフィルタリングや列の追加・削除など、様々な加工機能が用意されています。以下は、一部の列だけを抽出する例です。

上記のコードでは、DataFrameの`column1`と`column2`の列だけを抽出して、新しいDataFrameを作成しています。
【5. データの集計】
DataFrameに格納されたデータを集計することもできます。Pandasには、グループ化や統計量の計算など、様々な集計機能が用意されています。以下は、ある列の値ごとにグループ化して、平均値
を計算する例です。

上記のコードでは、DataFrameを`column1`の値ごとにグループ化して、各グループの平均値を計算しています。
【6. データの可視化】
最後に、Pandasを使ってデータを可視化する方法を紹介します。Pandasには、Matplotlibというデータ可視化ライブラリと統合された機能が用意されています。以下は、折れ線グラフを作成する例です。

上記のコードでは、Matplotlibを`plt`としてインポートし、DataFrameの`column1`と`column2`を使って、折れ線グラフを作成しています。
【まとめ】
以上が、Pandasを使ったデータ分析の基礎的な使い方です。Pandasには、データの結合や欠損値の処理など、より高度な機能も用意されています。ぜひ、実際のデータを使って、Pandasを使ったデータ分析に挑戦してみてください。
【Pythonにおける数値計算の基礎】NumPyの使い方と基本的な操作方法
【Pythonにおける数値計算の基礎】NumPyの使い方と基本的な操作方法
Pythonは、数値計算に必要な機能を提供するNumPyライブラリが含まれています。NumPyを使用することで、多次元配列の操作や数学的な計算が容易になります。本記事では、NumPyを使用してPythonで数値計算を行う方法を紹介します。
【目次】
1. NumPyとは
2. NumPyの基本的なデータ型
3. NumPy配列の作成方法
4. NumPy配列の基本的な操作
5. 数値計算の例
【1. NumPyとは】
NumPyは、Pythonにおける数値計算ライブラリであり、高速な数値計算が可能です。NumPyを使用することで、Pythonでの科学的なプログラミングが容易になります。NumPyは、数学的な処理や配列操作が多数用意されており、多くの数値計算ライブラリやデータサイエンスツールでも使用されています。
【2. NumPyの基本的なデータ型】
NumPyでは、基本的な数値型が定義されており、これらの型を用いて多次元配列を作成することができます。主なデータ型は以下の通りです。
- int8, int16, int32, int64
- uint8, uint16, uint32, uint64
- float16, float32, float64, float128
- complex64, complex128, complex256
【3. NumPy配列の作成方法】
NumPy配列は、Pythonの標準リストから作成することができます。ただし、NumPy配列は標準リストよりも効率的な処理が可能であり、多次元配列を扱うことができます。NumPy配列の作成方法は以下の通りです。

【4. NumPy配列の基本的な操作】
NumPy配列では、多数の基本的な操作をサポートしています。以下にNumPy配列の基本的な操作を紹介します。
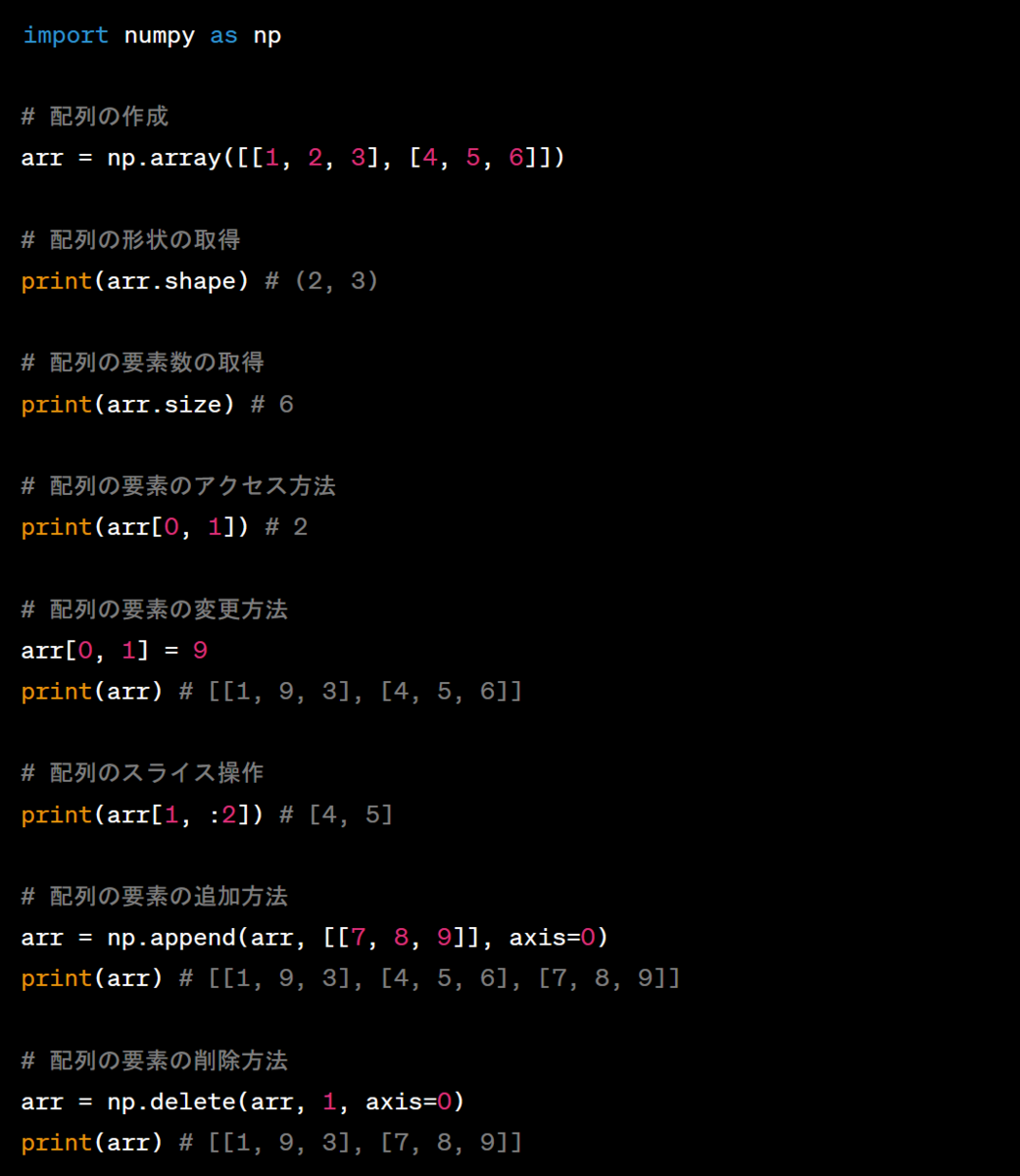
- 配列の次元数の取得:`ndim`属性
- 配列の形状の取得:`shape`属性
- 配列の要素数の取得:`size`属性
- 配列のデータ型の取得
:`dtype`属性
- 配列の要素へのアクセス方法:添え字を指定してアクセス
- 配列の要素の変更方法:添え字を指定して値を代入
- 配列のスライス操作:`:`を使って範囲を指定
- 配列の要素の追加方法:`append()`メソッドを使う
- 配列の要素の削除方法:`delete()`メソッドを使う
以下に、NumPy配列の操作の例を示します。
【5. 数値計算の例】
NumPyを使用することで、数値計算が容易になります。以下に、数値計算の例を示します。

【まとめ】
本記事では、Pythonにおける数値計算の基礎的な処理について解説しました。NumPyを使うことで、数値計算を効率的に行うことができます。NumPy配列の作成方法、基本的な操作方法、数値計算の例を紹介しました。NumPyを使って、Pythonで数値計算を効率的に行うことができるようになりました。今回紹介した内容は、Pythonの数値計算の基礎であるため、深く学ぶ場合は、この記事を参考に、更に学習を進めていくことをおすすめします。
【Pythonでのデータサイエンス入門】初心者でも分かる基礎解説と実践例
【Pythonでのデータサイエンス入門】初心者でも分かる基礎解説と実践例

Pythonは、データサイエンス分野で最も広く使用されているプログラミング言語の一つです。特に、NumPyやPandasなどのライブラリのおかげで、Pythonはデータ分析や機械学習などの分野で強力なツールとなっています。本記事では、Pythonを使ったデータサイエンスの基礎について解説します。
【目次】
1. データサイエンスとPythonの関係性
2. NumPyによる数値計算の基礎
3. Pandasによるデータ分析の基礎
4. Matplotlibによるデータ可視化の基礎
5. 実践例:Jupyter Notebookを使ったデータ分析
【1. データサイエンスとPythonの関係性】
データサイエンスとは、データから意味を抽出し、ビジネスや科学的な問題を解決することを目的とした学問分野です。Pythonは、このようなデータサイエンスにおいて、非常に重要な役割を果たしています。Pythonは、開発が容易で、コミュニティが大きく、豊富なライブラリが存在することが特徴です。
【2. NumPyによる数値計算の基礎】
NumPyは、Pythonで数値計算を行うためのライブラリです。NumPyを使うことで、高速な数値計算を実行することができます。以下の記事で詳しく解説しています
【3. Pandasによるデータ分析の基礎】
Pandasは、Pythonでデータ分析を行うためのライブラリです。Pandasを使うことで、データの読み込み、整形、集計、統計処理などが簡単に行えます。以下の記事で詳しく解説しています
【4. Matplotlibによるデータ可視化の基礎】
Matplotlibは、Pythonでグラフを描画するためのライブラリです。Matplotlibを使うことで、データを視覚化し、洞察を得ることができます。以下の記事で詳しく解説しています
【5. 実践例:Jupyter Notebookを使ったデータ分析】
Jupyter Notebookは、Pythonを使ったデータ分析のための環境です。Jupyter Notebookを使うことで、Pythonのコードと実行結果を一緒に表示できるため、データ分析の過程が視覚的に理解できます。以下の記事で詳しく解説しています
【まとめ】
Pythonを使ったデータサイエンスの基礎について解説しました。NumPy、Pandas、Matplotlibを使って、数値計算、データ分析、データ可視化を行う方法を紹介しました。また、Jupyter Notebookを使った実践的な例も紹介しました。これらのライブラリを使えば、初心者でもデータサイエンスの基礎的な処理を簡単に行うことができます。
MVCモデルとは?Webアプリケーション設計における重要性と使い方
MVCモデルとは??

MVCモデルとは、Model-View-Controllerの略称であり、Webアプリケーションの設計パターンの1つです。MVCモデルは、アプリケーション内の各要素を独立して管理し、開発者がアプリケーションの構造を明確に理解することを容易にします。
MVCモデルには3つの主要な要素があります:Model(モデル)、View(ビュー)、Controller(コントローラ)。それぞれの役割を見ていきましょう。
モデルは、アプリケーションのデータやビジネスロジックを管理する要素です。データベースからデータを取得し、ビジネスロジックを実行することができます。モデルは通常、データの永続性を管理するためにORM(Object Relational Mapping)を使用します。
ビューは、アプリケーションのユーザーインターフェースを管理する要素です。HTML、CSS、JavaScriptなどを使用して、データを表示し、ユーザーがアプリケーションを操作できるようにします。ビューは、一般的に、特定のデータに対応するHTMLテンプレートを持ちます。
コントローラは、アプリケーションのビジネスロジックとビューをつなぐ要素です。コントローラは、ユーザーの入力を処理し、それに基づいて適切なモデルを呼び出して、必要なビジネスロジックを実行します。そして、それらの結果をビューに渡します。つまり、コントローラは、モデルとビューの仲介役を担います。
MVCモデルは、開発者がアプリケーションの構造をより明確に理解できるようにすることで、アプリケーションの開発を容易にします。また、モデルとビューを分離することで、アプリケーションの柔軟性と拡張性を向上させることができます。さらに、コントローラによって、アプリケーションのビジネスロジックとビューが疎結合になります。これによって、アプリケーションのメンテナンスが容易になります。
一般的に、MVCモデルはWebアプリケーションの設計に広く使用されています。MVC
モデルは、アプリケーション内でデータを保持し、必要に応じて変更する責任を持ちます。ビューは、ユーザーに見える部分を担当し、ユーザーがインタラクションするために必要なインターフェースを提供します。そして、コントローラは、ビューとモデルの間に仲介者として働き、ビューに必要なデータを提供し、ユーザーの操作に基づいてモデルを更新します。
MVCモデルを使用することで、複雑なWebアプリケーションを構築することができます。また、MVCモデルは、アプリケーションの各要素を独立してテストすることができるため、アプリケーションの品質を確保するのに役立ちます。
さらに、MVCモデルは、Webアプリケーションの開発を協力的に行うためのベストプラクティスを提供します。コントローラを介して、複数の開発者が同じモデルやビューを利用することができます。そして、モデルとビューが疎結合であるため、変更が必要な場合でも、開発者は特定の部分のみを変更することができます。
MVCモデルは、Webアプリケーションの設計に広く使用されているため、多くのプログラミング言語やフレームワークでサポートされています。例えば、Ruby on Rails、Django、Springなどのフレームワークでは、MVCモデルを基盤としたWebアプリケーションの開発が可能です。
まとめ
総括すると、MVCモデルは、Webアプリケーションの設計において重要な役割を果たしています。モデル、ビュー、コントローラの3つの要素をうまく分離し、それぞれの責任を明確にすることで、Webアプリケーションの柔軟性、拡張性、テスト性を向上させることができます。
オブジェクト指向プログラミングとは?特徴や実装方法について解説
1. オブジェクト指向プログラミングとは
オブジェクト指向プログラミングとは、プログラムを構成する要素を「オブジェクト」という単位で捉え、それぞれのオブジェクトがデータとメソッド(処理)を持つことによって、複雑な処理を分かりやすく表現するプログラミング手法です。OOPは、従来の手続き型プログラミングに比べて、プログラムの再利用性が高く、保守性が向上するというメリットがあります。
2. オブジェクト指向プログラミングの特徴
オブジェクト指向プログラミングには、以下のような特徴があります。
2-1. カプセル化
オブジェクト指向プログラミングでは、オブジェクトが持つデータやメソッドを、他のオブジェクトから隠蔽することができます。このように、オブジェクトの内部状態を保護することを「カプセル化」と呼びます。カプセル化によって、オブジェクトの内部状態を外部から直接変更されることを防ぎ、プログラムの信頼性を高めることができます。
2-2. 継承
オブジェクト指向プログラミングでは、既存のクラスを継承して新しいクラスを作成することができます。継承によって、既存のクラスの機能を引き継ぎつつ、新しい機能を追加することができます。このように、クラスの階層を構成することで、プログラムの構造を効率的に設計することができます。
2-3. ポリモーフィズム
オブジェクト指向プログラミングでは、同じクラスから作成された複数のオブジェクトが、同じメソッドを呼び出した場合でも、それぞれのオブジェクトが持つデータに応じた異なる処理を行うことができます。このように、同じメソッドを呼び出しても異なる処理を行うことを「ポリモーフィズム」と呼びます。ポリモーフィズムによって、プログラムの柔軟性を高めることができます。
3. オブジェクト指向プログラミングの実装方法
オブジェクト指向プログラミングを実装するためには、以下のような手順を踏む必要があります。
3-1. クラスの設計
オブジェクト指向プログラミングでは、クラスを設計することが重要です。クラスは、オブジェクトの設計図とも言えます。クラスには、オブジェクトが持つデータ(インスタンス変数)と、オブジェクトが行う処理(メソッド)を定義します。
3-2. オブジェクトの生成
クラスを定義したら、そのクラスからオブジェクトを生成することができます。オブジェクトを生成することを「インスタンス化」と呼びます。インスタンス化することによって、クラスで定義したデータやメソッドを持つオブジェクトが作成されます。
3-3. オブジェクト間のやりとり
オブジェクト指向プログラミングでは、オブジェクト同士がデータやメソッドをやりとりすることができます。オブジェクト同士がやりとりする場合は、メッセージを送ることで行います。メッセージを受け取ったオブジェクトは、それに応じた処理を行います。
4. まとめ
オブジェクト指向プログラミングは、現実世界をモデル化し、プログラムに反映させるための手法です。カプセル化、継承、ポリモーフィズムといった特徴を持ち、プログラムの再利用性が高く、保守性が向上します。クラスの設計、オブジェクトの生成、オブジェクト間のやりとりといった手順を踏むことで、オブジェクト指向プログラミングを実装することができます。
C言語とC++の違いとは?
C言語とC++の違いについて
C言語とC++は、どちらもプログラミング言語であり、C言語がC++の起源となっています。しかし、C言語とC++にはいくつかの違いがあります。今回は、C言語とC++の違いについて詳しく解説していきます。
まず、C言語とC++の最も大きな違いは、オブジェクト指向プログラミングのサポートの有無です。C言語は手続き型プログラミング言語であり、オブジェクト指向プログラミングをサポートしていません。一方、C++はオブジェクト指向プログラミングをサポートしており、クラスや継承などの機能があります。
次に、C++はC言語の拡張版であり、C言語の構文やライブラリを引き継いでいます。そのため、C++はC言語と互換性があり、C言語で書かれたプログラムをC++でコンパイルすることができます。しかし、C++はC言語よりも多数の機能を持っており、より高水準なプログラミングを行うことができます。
また、C++はメモリ管理についてより高度な制御が可能です。C++では、new演算子を使ってメモリを動的に確保し、delete演算子を使ってメモリを解放することができます。一方、C言語では、malloc関数を使ってメモリを確保し、free関数を使ってメモリを解放します。
さらに、C++ではオーバーロードとテンプレートが利用できます。オーバーロードは、同じ関数名を複数の引数型で定義することができ、関数名の再利用を可能にします。テンプレートは、クラスや関数の汎用化を可能にするための仕組みです。
最後に、C++では例外処理が利用できます。例外処理は、プログラムの実行中に予期せぬエラーが発生した場合に、エラー処理を行うための仕組みです。C言語では例外処理がサポートされていないため、エラー処理はif文やswitch文などで行う必要があります。
以上が、C言語とC++の主な違いについての解説でした。C言語とC++はどちらもプログラミング言語であり、目的によって使い分けることが重要です.